High-volume inference on a three-vendor sovereign cluster








Most production inference clusters today are single-vendor — not because it's an optimal design, but because it's the simplest way to configure a cluster.
That is starting to change. Procurement cycles bring new generations alongside older ones, supply constraints push teams across vendors, and the cost gap between accelerators makes a one-size-fits-all fleet increasingly expensive to defend. Real production fleets are accumulating heterogeneity whether or not the architecture planned for it.
This is an opportunity to unlock real value: lower-cost accelerators can absorb low-priority workloads while premium hardware handles latency-sensitive paths, stranded capacity gets reclaimed, and the organization is no longer held hostage to one supplier's roadmap or pricing. The case is stronger still for sovereign and on-premise deployments, where data residency, regulatory alignment, and the long-term economics of high-volume inference are pushing AI workloads off centralized hyperscaler stacks.
But making it work in practice is hard. Divergent driver stacks, firmware versions, container images, hardware-specific attention kernels, and the absence of standardized performance comparisons across accelerators all combine to make a coherent serving layer over a heterogeneous fleet a non-trivial systems problem.
Setup
To evaluate llm-d on a heterogeneous environment, we ran experiments on the NxtGen sovereign cloud's mixed GPU environment, with the following accelerator pools within a single OpenShift AI cluster:
| Pool | Hardware | Count |
|---|---|---|
| NVIDIA | H100-NVL (2 nodes × 2 GPUs) | 4 |
| AMD | MI325X (1 node) | 8 |
| Intel | Gaudi3 (1 node) | 8 |
All nodes are connected over a shared 100 G RoCE network. We pinned each vLLM replica to a single accelerator card (TP = 1) to maximize the number of independent serving instances and exercise the routing layer.
Models served:
ibm-granite/granite-4.1-8b— 8 B parameter, hybrid-Mamba transformersarvamai/sarvam-30b— 30 B MoE, Indic-multilingual model with custom vLLM kernels
The workload is the prefill-heavy shared_prefix_synthetic from inference-perf: a long shared system prompt + short question + decode-tolerant output (~7.2K input tokens + 1K output tokens). This matches production RAG, chat, and citizen-services traffic profiles where prefix-cache routing has the most room to win.
Prefix-aware caching
We deployed llm-d v0.0.7 with precise prefix-cache-aware routing. Each vendor's pods are deployed as a separate Helm release in the same namespace; only the nodeSelector and a small set of vendor-specific tuning flags (e.g. Gaudi's --block-size 128, --max-num-seqs 256, VLLM_BUILD pin) vary between releases. All pods carry the same selector labels and register with a single InferencePool maintained by llm-d's router. For the baseline, we use a ClusterIP service over the same set of pods to drive plain Kubernetes round-robin scheduling — same pods, same vLLM, same flags; only the routing layer differs.
Across every pool we tested — single-vendor (NVIDIA-only / AMD-only / Gaudi-only) and heterogeneous (NVIDIA+AMD, NVIDIA+AMD+Gaudi) — llm-d's prefix-cache-aware routing consistently wins over plain k8s round-robin on both throughput and time-to-first-token (TTFT). The advantage grows with pool size and heterogeneity.
| Pool | Pods | Model | Throughput edge (llm-d vs k8s) | TTFT edge |
|---|---|---|---|---|
| NVIDIA-only | 4 H100-NVL | granite-4.1-8b | +25–36% | 16× |
| NVIDIA-only | 4 H100-NVL | sarvam-30b | 2× | 22× |
| AMD-only | 8 MI325X | granite-4.1-8b | +79% | 21× |
| AMD-only | 8 MI325X | sarvam-30b | +85% (29 K vs 17 K out tok/s) | 5× |
| Gaudi-only | 8 Gaudi3 | granite-4.1-8b | +34% | 18× |
| NVIDIA + AMD | 12 | granite-4.1-8b | +85% (19.4 K vs 10–11 K) | 3.4–5.6× |
| NVIDIA + AMD | 12 | sarvam-30b | ~3× @ 200 qps | 2.85–4.54× |
| NVIDIA + AMD + Gaudi | 20 | granite-4.1-8b | +91% @ 85 qps | 5.4× |
Why llm-d wins biggest on heterogeneous pools: k8s round-robin spreads requests evenly regardless of pod speed, so a single slow accelerator becomes a queueing sink that drags total throughput down. llm-d's prefix-cache-aware EPP routes around saturated pods and concentrates cache hits on warm ones, so heterogeneity is no longer a penalty.
Single-vendor pools — granite-4.1-8b
We start with the per-vendor baselines so the heterogeneous results below have a reference point. All runs use ~7.2K ISL + 1K OSL.
4× NVIDIA H100-NVL. llm-d improves TTFT by up to 16× compared to k8s, and output throughput by 25–36%.
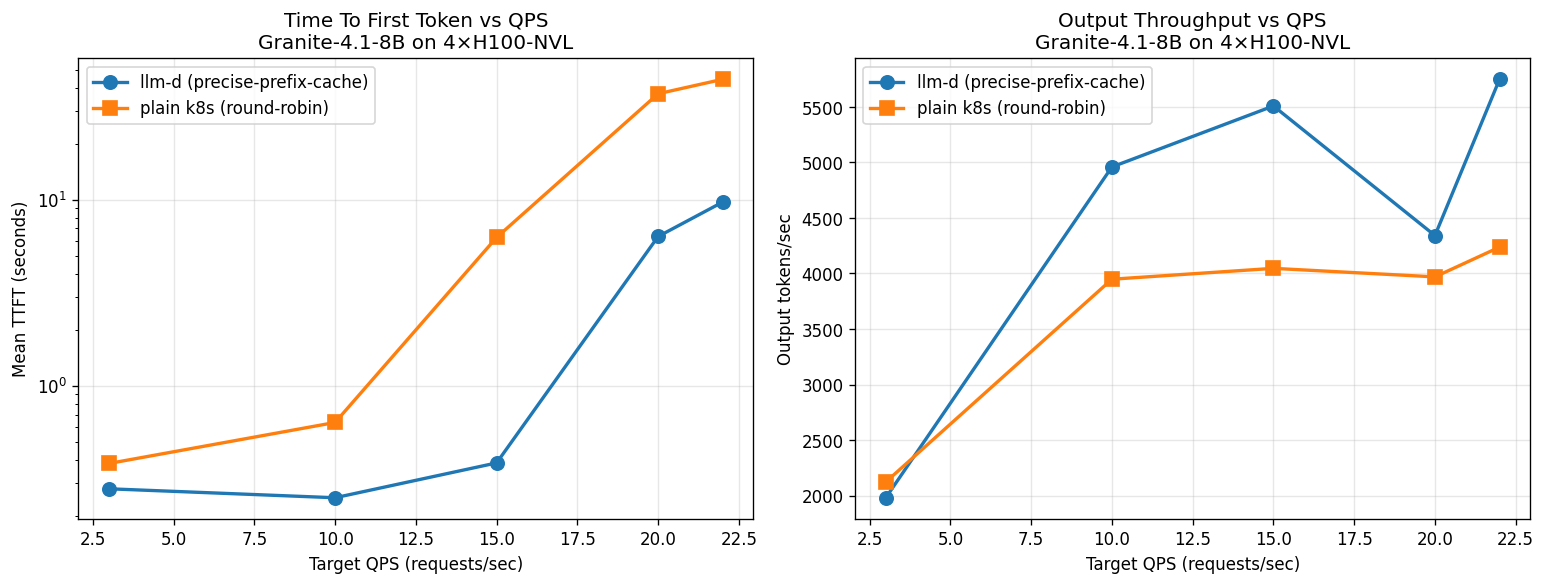
8× AMD MI325X. llm-d delivers up to 21× better TTFT and +79% throughput vs k8s round-robin on this AMD-only granite deployment.
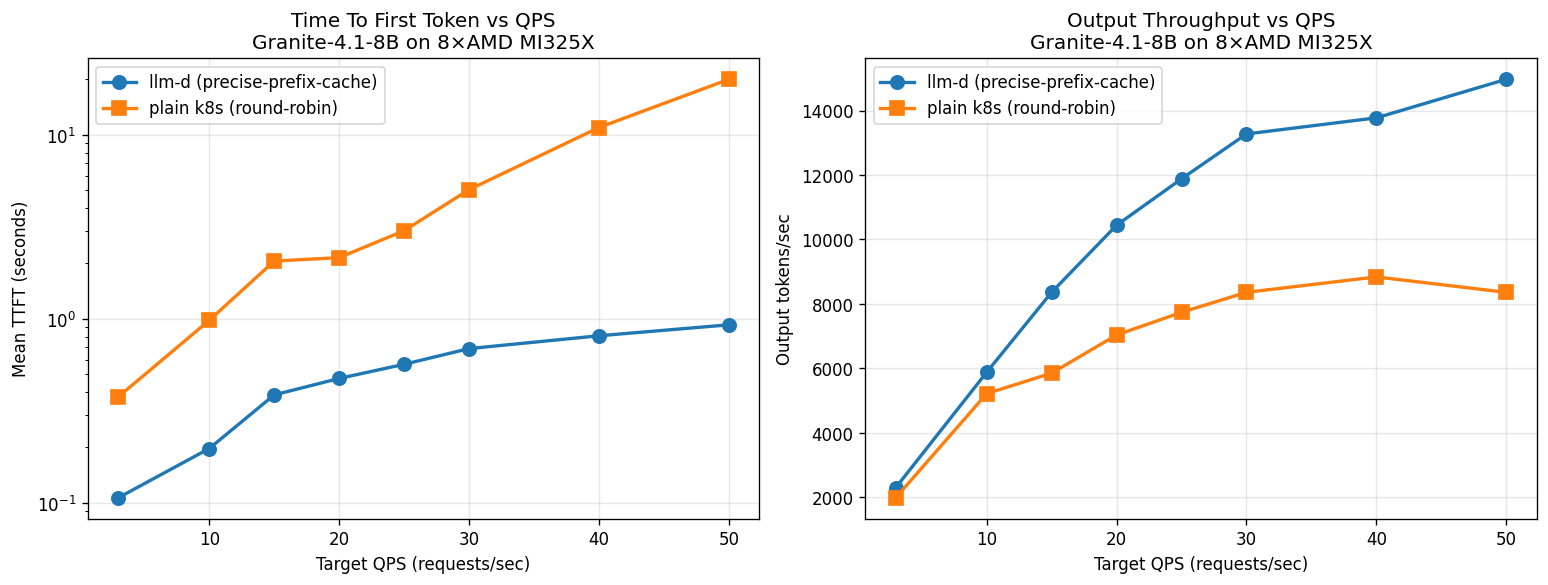
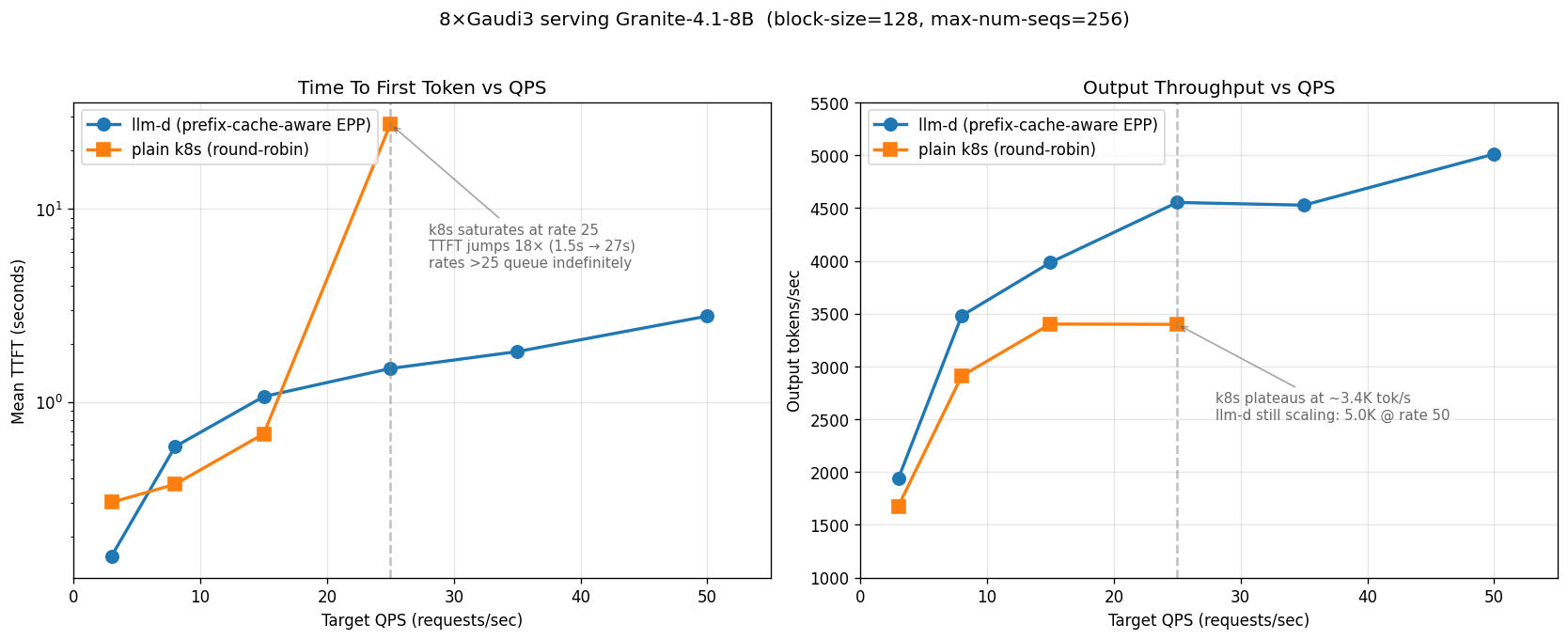
8× Intel Gaudi3. At saturation (rate 25), llm-d delivers +34% throughput and ~18× better TTFT vs plain k8s round-robin.
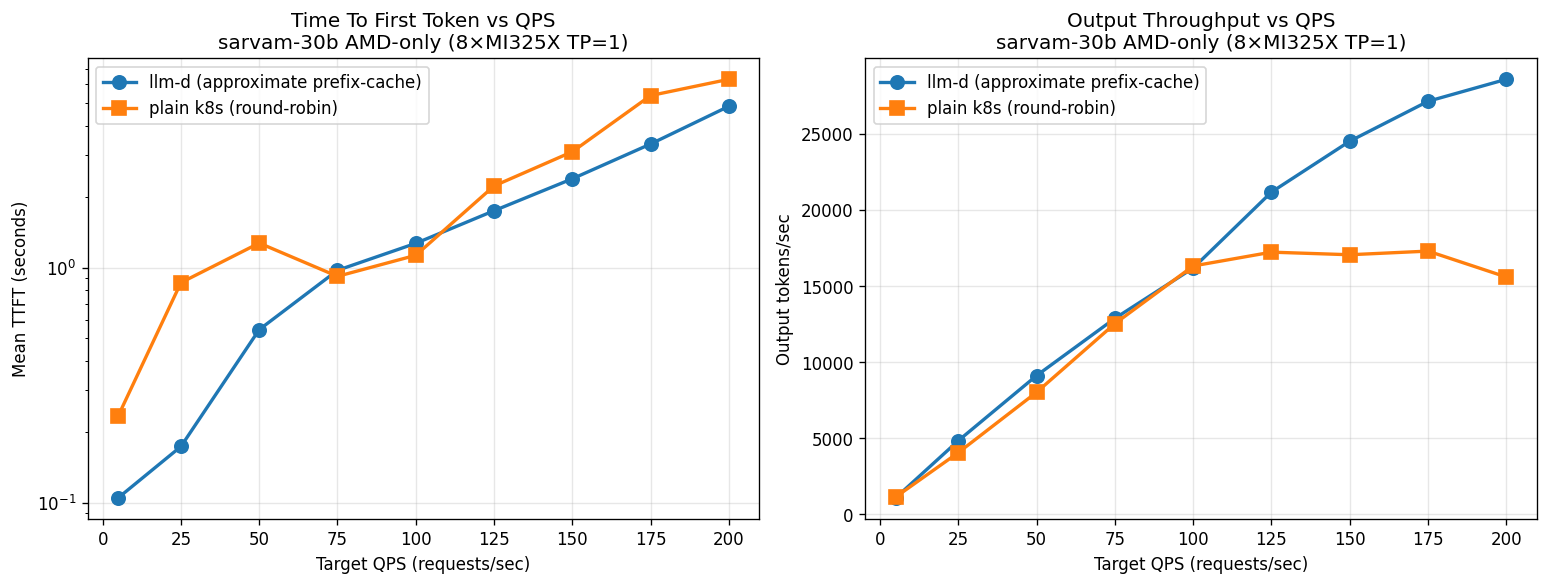
Single-vendor pools — sarvam-30b (multilingual MoE)
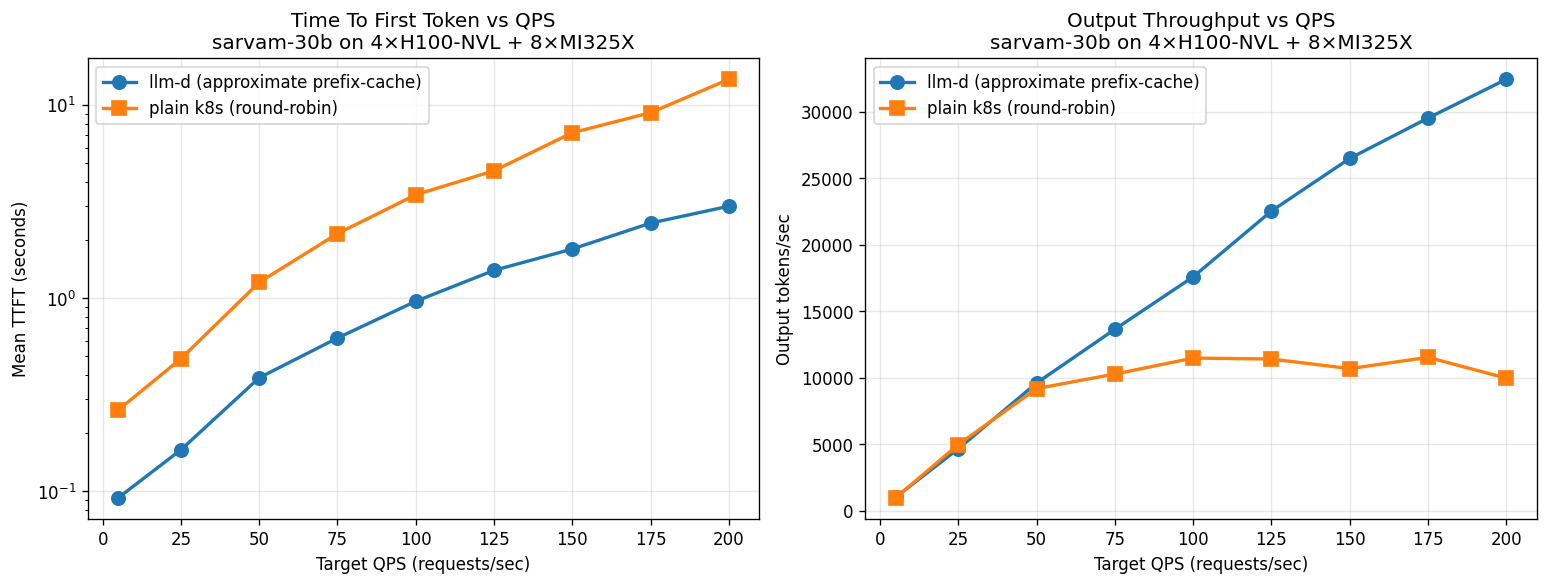
4× NVIDIA H100-NVL. llm-d delivers 2× the throughput and 22× better TTFT. k8s saturates around rate 25–30; llm-d keeps scaling.
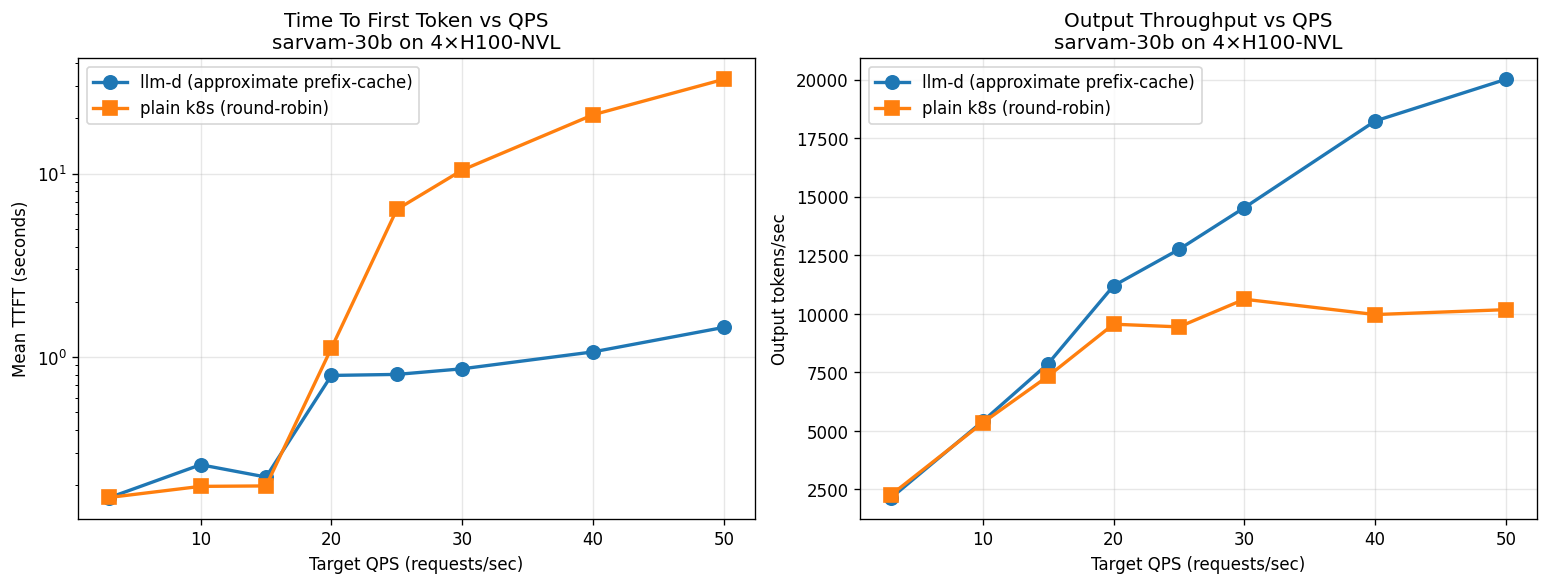
8× AMD MI325X. While k8s throughput plateaus at 15–17 K out tok/s, llm-d goes up to 29 K — 85% higher throughput. TTFT-wise llm-d is up to 5× faster at lower rates.
We were unable to run sarvam-30b on Intel Gaudi3 due to software compatibility issues, but plan to work with the llm-d community to bridge this gap in the future.
Heterogeneous pools — where llm-d wins biggest
NVIDIA + AMD (12 pods, granite-4.1-8b). While k8s throughput plateaus at 10–11 K tok/s, llm-d goes up to 19.4 K — 85% higher throughput. TTFT-wise llm-d is 3.4–5.6× faster at higher rates.
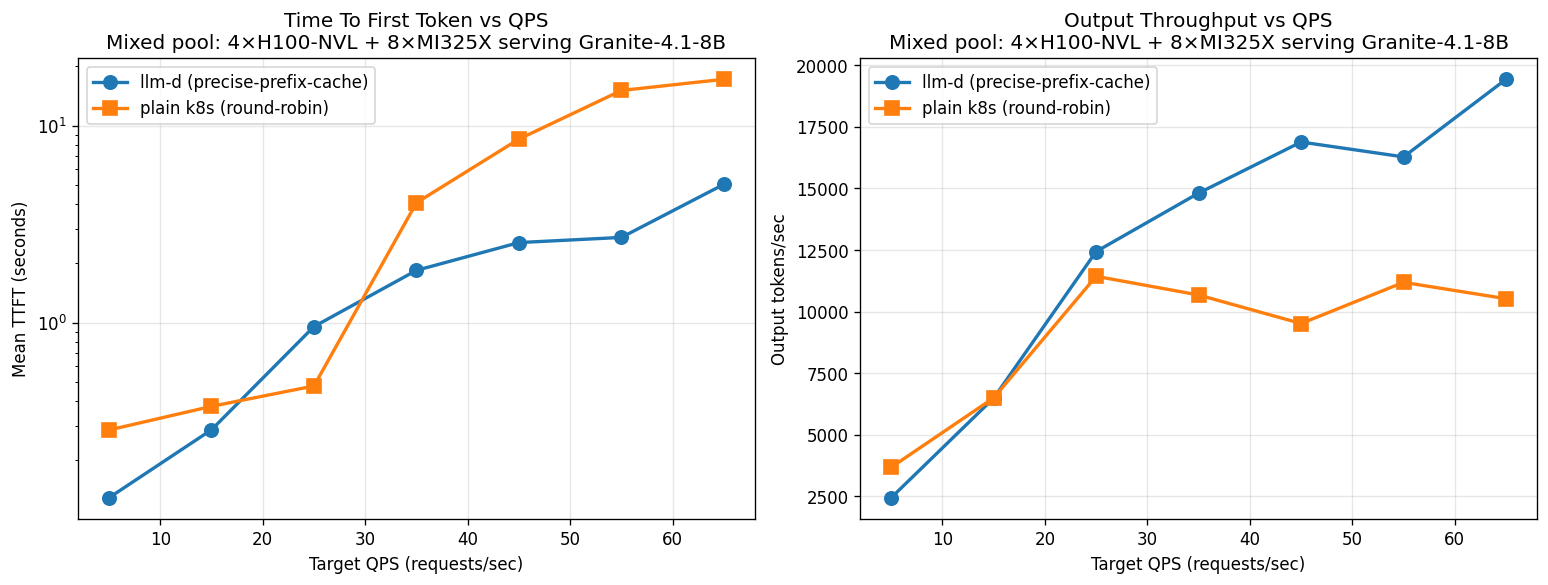
NVIDIA + AMD (12 pods, sarvam-30b). llm-d brings down TTFT by 2.85–4.54× and increases throughput by close to 3× at rate 200. llm-d wins biggest in this mixed pool — round-robin is most punished by heterogeneous capacity, and llm-d's prefix-aware routing avoids this trap.
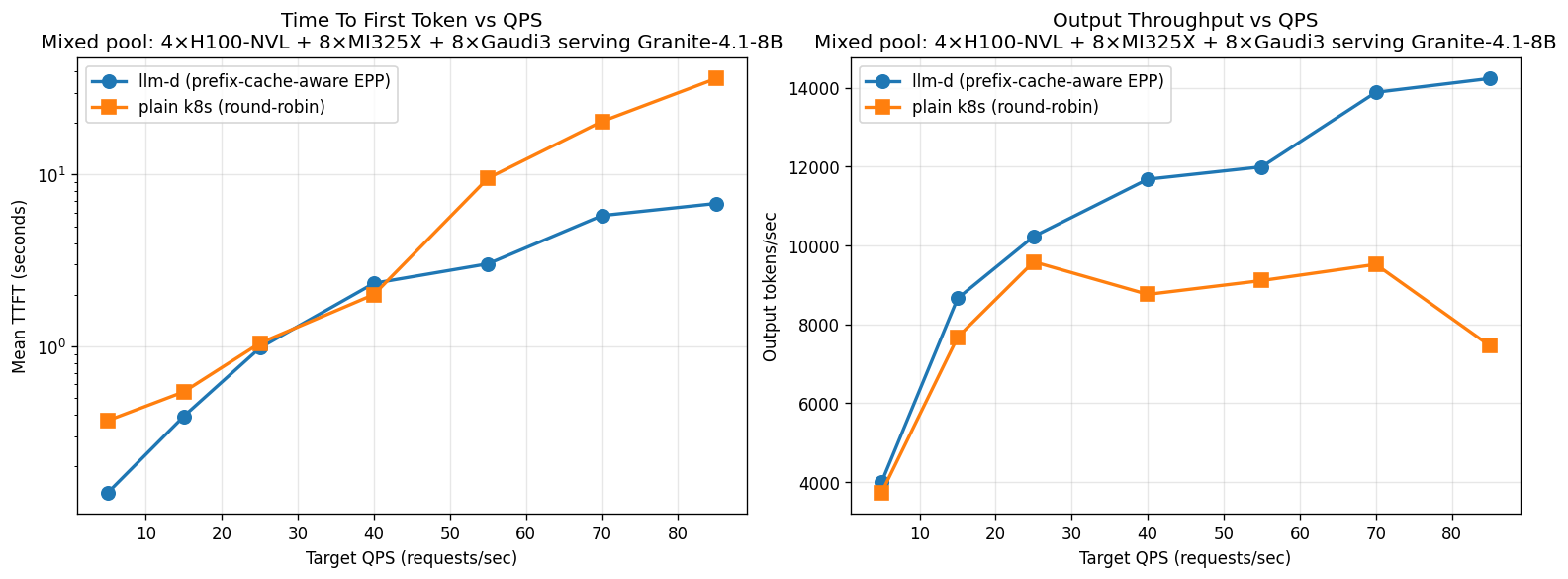
NVIDIA + AMD + Gaudi (20 pods, granite-4.1-8b). The 20-pod 3-vendor pool delivers 14.2 K out tok/s peak with llm-d vs 9.6 K with k8s round-robin. k8s saturates at rate 25 and declines to 7.5 K at rate 85 (queue depth dominates) — llm-d delivers +91% throughput at the same load. TTFT at rate 85: llm-d 6.8 s, k8s 36.4 s (5.4× better).
What's next
Cross-accelerator P/D disaggregation. We plan to take heterogeneous inference to the next level by enabling prefill and decode to run on mixed accelerator types within the same cluster — for example, routing compute-heavy prefill to NVIDIA H100 nodes and memory-bandwidth-intensive decode to AMD MI325X nodes (or vice versa), based on where each phase runs most efficiently. This requires the KV cache transfer library (e.g. NIXL) to work across different GPU vendors on each end, an active area of development in the llm-d community.